




йҡҸзқҖиҫ№зјҳи®Ўз®—зӣёе…іжҠҖжңҜзҡ„йҖҗжёҗжҲҗзҶҹпјҢиҫ№зјҳеә”з”Ёзҡ„з§Қзұ»д№ҹе‘ҲзҺ°еӨҡж ·еҢ–еҸ‘еұ•гҖӮIDC 2023 е№ҙеҸ‘еёғзҡ„гҖҠе…Ёзҗғиҫ№зјҳж”ҜеҮәжҢҮеҚ—гҖӢеҪ’зәіеҮә 400 еӨҡз§Қи·ҹиҫ№зјҳзӣёе…ізҡ„еә”з”ЁвҖ”вҖ”иҝҷжҳҜеңЁд»Һ 9 дёӘең°зҗҶеҢәеҹҹгҖҒ17 дёӘжҠҖжңҜеёӮеңәгҖҒ6 дёӘжҠҖжңҜйўҶеҹҹе’Ң 19 дёӘиЎҢдёҡеҪ“дёӯжұҮжҖ»еҮәжқҘзҡ„гҖӮ
иҫ№зјҳи®Ўз®—зҡ„еӨҚжқӮе’Ңиҫ№зјҳеә”з”Ёзҡ„еӨҡж ·пјҢеҫҲе®№жҳ“и®©дәәиҒ”жғіеҲ°дёҖдёӘе…ёж•…вҖ”вҖ”вҖңзӣІдәәж‘ёиұЎвҖқгҖӮеңЁиҫ№зјҳи®Ўз®—з”ҹжҖҒдёӯпјҢжҜҸдёӘдәәгҖҒжҜҸдёӘиЎҢдёҡгҖҒжҜҸдёҖдёӘе…¬еҸёзҡ„ж–№жЎҲпјҢйғҪеҸӘиғҪиҰҶзӣ–еҲ°иҫ№зјҳи®Ўз®—еңәжҷҜзҡ„дёҖйғЁеҲҶгҖӮеҫҲйҡҫжүҫеҲ°дёҖдёӘе…¬еҸё/з»„з»Үзҡ„жҠҖжңҜ/дә§е“Ғ/и§ЈеҶіж–№жЎҲпјҢиғҪеӨҹиҰҶзӣ–иҫ№зјҳеә”з”ЁжүҖжңүеңәжҷҜзҡ„йңҖжұӮгҖӮеҰӮжһңиҰҒдёәжҜҸдёӘиҫ№зјҳз”ЁдҫӢжһ„е»әдё“й—Ёзҡ„и§ЈеҶіж–№жЎҲпјҢжҜ«ж— з–‘й—®е°ҶйҷҚдҪҺиҫ№зјҳеә”з”Ёзҡ„дәӨд»ҳйҖҹеәҰпјҢжҸҗеҚҮжҲҗжң¬е’ҢеӨҚжқӮеәҰпјҢеҗҢж—¶иҙЁйҮҸе’Ңз”ЁжҲ·дҪ“йӘҢйҡҫд»ҘдҝқиҜҒпјӣиҖҢеҰӮжһңиҰҒдёәиҫ№зјҳи®Ўз®—жҸҗдҫӣж ҮеҮҶеҢ–зҡ„гҖҒиө„жәҗе’ҢжөҒзЁӢй«ҳеәҰж•ҙеҗҲзҡ„и§ЈеҶіж–№жЎҲпјҢе°ұйңҖиҰҒеҜ№иҫ№зјҳеә”з”Ёзҡ„жҷ®йҒҚзү№зӮ№еҸҠе…¶иө„жәҗйңҖжұӮжңүж·ұе…Ҙзҡ„дәҶи§Је’ҢеҮҶзЎ®зҡ„еҲҶжһҗгҖӮ
еҹәдәҺжӯӨпјҢеңЁиҝҷзҜҮж–Үз« дёӯпјҢжҲ‘们е°ҶиҒҡз„ҰеҹәзЎҖжһ¶жһ„еұӮйқўпјҢйҖҡиҝҮеҲҶжһҗиҫ№зјҳеә”з”ЁеҜ№ IT еҹәзЎҖжһ¶жһ„зҡ„жҠҖжңҜйңҖжұӮпјҢдёәиҜ»иҖ…жҸҗдҫӣзҺ°йҳ¶ж®өйҖӮеҗҲж”ҜжҢҒиҫ№зјҳз”ЁдҫӢзҡ„жһ¶жһ„еҸӮиҖғгҖӮ
иҫ№зјҳеә”з”ЁеҜ№еҹәзЎҖжһ¶жһ„зҡ„жҠҖжңҜйңҖжұӮеҲҶжһҗ
ж”Ҝж’‘иҫ№зјҳеә”з”Ёзҡ„ж•ҙдҪ“жһ¶жһ„зү№зӮ№
Gartner еҜ№дәҺиҫ№зјҳи®Ўз®—е’Ңдә‘зҡ„жҠҖжңҜжһ¶жһ„зҡ„еҲҶжһҗпјҢеҸҜд»Ҙеё®еҠ©жҲ‘们д»Һж•ҙдҪ“жһ¶жһ„зҡ„и§’еәҰпјҢжӣҙеҘҪең°зҗҶи§Јиҫ№зјҳеә”з”Ёзӣёе…ізҡ„жҠҖжңҜеҸҠеҲҶзұ»гҖӮиҫ№зјҳи®Ўз®—зҡ„еҹәзЎҖжһ¶жһ„еҲҶзұ»пјҢеёёеёёжҖ»з»“жҰӮеҶөдёәвҖңдә‘-иҫ№-з«ҜвҖқгҖӮеңЁ Gartner зҡ„еҹәзЎҖжһ¶жһ„жЁЎеһӢйҮҢпјҢвҖңи®ҫеӨҮиҫ№зјҳвҖқе°ұжҳҜжҲ‘们常иҜҙзҡ„вҖңз«ҜвҖқпјҢжӣҙдёҠйқўеҮ еұӮеҲҶеҲ«жҳҜзҪ‘е…іиҫ№зјҳгҖҒи®Ўз®—иҫ№зјҳгҖҒжң¬ең°ж•°жҚ®дёӯеҝғгҖҒеҢәеҹҹж•°жҚ®дёӯеҝғд»ҘеҸҠдә‘пјҲеҰӮдёӢеӣҫпјүгҖӮ

еӨ§е®¶еҜ№иҫ№зјҳеұӮзә§зҡ„еҲҶзұ»е’Ңе‘ҪеҗҚд№ҹдёҚз»ҹдёҖпјҡдҫӢеҰӮжҲ‘们常иҜҙзҡ„вҖңз«ҜвҖқи®ҫеӨҮпјҢиҝҷеңЁ Gartner зҡ„иҫ№зјҳи®Ўз®—еҲҶеұӮжһ¶жһ„еӣҫдёҠеҲ’еҲҶдёәвҖңи®ҫеӨҮиҫ№зјҳвҖқпјӣиҖҢиў« Gartner з§°дёәвҖңи®Ўз®—иҫ№зјҳвҖқзҡ„йғЁеҲҶпјҢжңүдәӣеҺӮе•Ҷзҡ„и§ЈеҶіж–№жЎҲз§°е…¶дёәвҖңзҺ°еңәиҫ№зјҳвҖқвҖҰвҖҰ
еҜ№з…§дёҠеӣҫзҡ„еұӮзә§пјҢвҖңи®ҫеӨҮз«ҜвҖқгҖҒвҖңзҪ‘е…іиҫ№зјҳвҖқеҸҜд»Ҙз»ҹз§°дёәвҖңиҝңз«Ҝиҫ№зјҳвҖқпјҲжҲ–вҖңи®ҫеӨҮиҫ№зјҳвҖқпјүгҖҒд»Һ вҖңи®Ўз®—иҫ№зјҳвҖқеҲ°вҖңжң¬ең°ж•°жҚ®дёӯеҝғвҖқиҝҷйғЁеҲҶеҸҜз§°дёәвҖңиҝ‘з«Ҝиҫ№зјҳвҖқпјҲеҜ№еә”еҲҶж”ҜеҠһе…¬е®ӨгҖҒеҲҶж”Ҝж•°жҚ®дёӯеҝғгҖҒеҲҶеёғејҸдә‘пјүпјҢжңҖдёҠеұӮжҳҜвҖңж•°жҚ®дёӯеҝғвҖқпјҲжҲ–вҖңдёӯеҝғдә‘вҖқпјүгҖӮ
иҝҷз§ҚеҲҶеұӮеҲҶзұ»ж–№ејҸдё»иҰҒжҳҜеҹәдәҺд»ҘдёӢдёүдёӘз»ҙеәҰеҜ№иҫ№зјҳеә”з”ЁеҸҠе…¶жүҖеңЁзҡ„з«ҷзӮ№иҝӣиЎҢиЎЎйҮҸпјҡ
1. ж•°жҚ®зҡ„еӯҳеӮЁе’ҢеӨ„зҗҶз»ҙеәҰ
вҖңиҝңз«Ҝиҫ№зјҳвҖқпјҲжҲ–вҖңи®ҫеӨҮиҫ№зјҳвҖқпјүдё»иҰҒиҙҹиҙЈж•°жҚ®зҡ„йҮҮйӣҶгҖҒжҡӮеӯҳе’Ңйў„еӨ„зҗҶгҖӮдҫӢеҰӮпјҢйҖҡиҝҮдј ж„ҹеҷЁгҖҒж‘„еғҸеӨҙгҖҒжҷәиғҪз»Ҳз«Ҝзӯүиҫ№зјҳи®ҫеӨҮиҺ·еҫ—зҡ„ж•°жҚ®пјҢе…Ҳз»ҸиҝҮдёҖеұӮиҝҮж»Өе’ҢзӯӣйҖүпјҢ然еҗҺеҶҚдј иҫ“еҲ°вҖңиҝ‘з«ҜвҖқгҖӮеҗ„з§Қиҫ№зјҳеә”з”ЁеҸҠзӣёеә”зҡ„иҫ№зјҳи®ҫеӨҮпјҢеңЁвҖңиҝңз«ҜвҖқдҪҚзҪ®еӨ§еӨҡжҳҜжүҝжӢ…зұ»дјјзҡ„д»»еҠЎгҖӮ
вҖңиҝ‘з«Ҝиҫ№зјҳвҖқжҳҜеҜ№жүҖжңүжқҘиҮӘвҖңиҝңз«Ҝиҫ№зјҳвҖқзҡ„ж•°жҚ®иҝӣиЎҢеӯҳеӮЁгҖҒеӨҮд»ҪгҖҒеҗҢжӯҘгҖҒеҲҶжһҗе’ҢеӨ„зҗҶзҡ„第дёҖз«ҷгҖӮ
вҖңж•°жҚ®дёӯеҝғвҖқпјҲжҲ–вҖңдёӯеҝғдә‘вҖқпјүйҖҡеёёз”ЁдәҺйӣҶдёӯеӯҳеӮЁгҖҒеӨҮд»Ҫе’Ңз®ЎзҗҶжқҘиҮӘжүҖжңүиҫ№зјҳзҡ„ж•°жҚ®гҖӮ
еӣ жӯӨпјҢжҜҸдёӘеҸӮдёҺиҫ№зјҳеә”з”Ёзҡ„з«ҷзӮ№пјҢжҳҜеҗҰжүҝжӢ…дҝқеӯҳж•°жҚ®зҡ„еҠҹиғҪгҖҒж•°жҚ®иғҪеӨҹдҝқеӯҳеӨҡд№…гҖҒиғҪеӨҹжҸҗдҫӣе“Әдәӣж•°жҚ®дҝқйҡңе’Ңж•°жҚ®жңҚеҠЎгҖҒйңҖиҰҒеҜ№ж•°жҚ®иҝӣиЎҢе“Әдәӣж·ұеәҰеҠ е·Ҙе’ҢеӨ„зҗҶпјҢиҝҷдәӣжҳҜеҢәеҲҶвҖңз«ҜвҖқ-вҖңиҫ№вҖқ-вҖңдә‘вҖқеұӮзә§жһ¶жһ„зҡ„йҮҚиҰҒдҫқжҚ®гҖӮ
2. еә”用延иҝҹж•Ҹж„ҹз»ҙеәҰ
еҜ№е»¶иҝҹй«ҳеәҰж•Ҹж„ҹзҡ„еә”з”ЁпјҲдҫӢеҰӮиҰҒжұӮеңЁжҜ«з§’зә§еҲ«еҒҡеҮәе“Қеә”зҡ„иҮӘеҠЁй©ҫ驶пјүпјҢйҖҡеёёеҝ…йЎ»иҝҗиЎҢеңЁвҖңиҝңз«Ҝиҫ№зјҳвҖқпјҢд»ҘдҪҝеә”з”Ёе°ҪйҮҸиҙҙиҝ‘иҫ№зјҳи®ҫеӨҮе’ҢдҪҝз”Ёиҫ№зјҳеә”з”Ёзҡ„дәәгҖӮ
еҜ№е»¶иҝҹдёҚж•Ҹж„ҹзҡ„еә”з”ЁеҲҷеҸҜиғҪеңЁж•°жҚ®дёӯеҝғеҶ…йғЁпјҢжҜ”еҰӮеҜ№йҮҮйӣҶзҡ„ж•°жҚ®иҝӣиЎҢи„ұж•ҸеӨ„зҗҶеҗҺиҝӣиЎҢй•ҝж—¶й—ҙи®ӯз»ғе’ҢеӯҰд№ гҖӮ
еҜ№е»¶иҝҹж•Ҹж„ҹзЁӢеәҰд»ӢдәҺеүҚдәҢиҖ…д№Ӣй—ҙзҡ„еә”з”ЁпјҢеҸҜд»ҘиҝҗиЎҢеңЁвҖңиҝ‘з«Ҝиҫ№зјҳвҖқз«ҷзӮ№гҖӮ
3. еә”з”Ёзҡ„з®ЎзҗҶе’ҢеҸ‘еёғз»ҙеәҰ
вҖңиҝ‘з«Ҝиҫ№зјҳвҖқе’ҢвҖңиҝңз«Ҝиҫ№зјҳвҖқдё»иҰҒжүҝжӢ…з®—жі•/зЁӢеәҸзҡ„жү§иЎҢе·ҘдҪңгҖӮеӣ дёәиҫ№зјҳеә”з”Ёзҡ„з®—жі•/зЁӢеәҸдёҚеҸҜиғҪжқҘиҮӘвҖңиҝңз«Ҝиҫ№зјҳвҖқпјҢеҸӘиғҪйҖҡиҝҮдёӯеҝғз«ҷзӮ№еҲҶеҸ‘еҲ°вҖңиҝ‘з«Ҝиҫ№зјҳвҖқжҲ–вҖңиҝңз«Ҝиҫ№зјҳвҖқиҝӣиЎҢжү§иЎҢгҖӮ
иҫ№зјҳеә”з”ЁдҪ“зі»дёӯзҡ„з®—жі•/зЁӢеәҸйңҖиҰҒеңЁдёӯеҝғз«ҷзӮ№пјҢйҖҡеёёжҳҜвҖңж•°жҚ®дёӯеҝғвҖқжҲ–вҖңдёӯеҝғдә‘вҖқпјҢиҝӣиЎҢйӣҶдёӯз®ЎзҗҶе’Ңз»ҹдёҖи°ғеәҰгҖӮеҚідҫҝжҳҜйңҖиҰҒй’ҲеҜ№дёҚеҗҢеҢәеҹҹзҡ„иҫ№зјҳеңәжҷҜдҪҝз”ЁдёҚеҗҢзҡ„з®—жі•/зЁӢеәҸпјҢйҖҡиҝҮдёӯеҝғз«ҷзӮ№иҝӣиЎҢз»ҹдёҖз®ЎзҗҶе’ҢеҸ‘еёғд№ҹжҳҜж•ҲзҺҮжңҖй«ҳзҡ„ж–№ејҸгҖӮ
д»Һд»ҘдёҠдёүдёӘз»ҙеәҰпјҢжҲ‘们еҸҜд»ҘжҜ”иҫғжё…жҷ°ең°еӢҫеӢ’еҮәиҫ№зјҳеә”з”Ёж¶үеҸҠеҲ°зҡ„дёүз§Қз«ҷзӮ№зҡ„зү№зӮ№иҪ®е»“гҖӮе®һи·өдёӯпјҢеҫҲеӨҡиҫ№зјҳеә”з”ЁеҜ№вҖң延иҝҹвҖқзҡ„иҰҒжұӮ并没жңүжё…жҷ°зҡ„з•ҢйҷҗпјҢеҜ№вҖңеә”з”Ёз®ЎзҗҶе’ҢеҸ‘еёғвҖқзҡ„ж–№ејҸд№ҹе°ҡжңӘеҪўжҲҗзЎ®е®ҡзҡ„жЁЎејҸпјҢзӣ®еүҚеҸӘжңүвҖңж•°жҚ®зҡ„еӯҳеӮЁе’ҢеӨ„зҗҶз»ҙеәҰвҖқжңүзӣёеҜ№жҜ”иҫғзЎ®е®ҡзҡ„ж ҮеҮҶгҖӮеҜ№з…§ Gartner зҡ„иҫ№зјҳи®Ўз®—еұӮзә§жЁЎеһӢпјҡвҖңзҪ‘е…іиҫ№зјҳвҖқеҸҠвҖңи®ҫеӨҮиҫ№зјҳвҖқпјҲиҝңз«Ҝиҫ№зјҳпјүдё»иҰҒжүҝжӢ…зҡ„жҳҜж•°жҚ®йҮҮйӣҶе’Ңдј иҫ“д»»еҠЎпјҢдёҚе…·еӨҮй•ҝжңҹдҝқеӯҳеӨ§йҮҸж•°жҚ®зҡ„иғҪеҠӣпјӣд»ҺвҖңи®Ўз®—иҫ№зјҳвҖқејҖе§ӢеҫҖдёҠзҡ„еұӮзә§пјҲиҝ‘з«Ҝиҫ№зјҳе’Ңж•°жҚ®дёӯеҝғпјүпјҢжүҝжӢ…зқҖи¶ҠжқҘи¶ҠеӨҡзҡ„ж•°жҚ®еӯҳеӮЁгҖҒеҲҶжһҗе’ҢеӨ„зҗҶд»»еҠЎгҖӮиҝҷеҜ№иҫ№зјҳеә”з”Ёзҡ„еҹәзЎҖжһ¶жһ„и®ҫи®Ўе’Ңе®һж–Ҫе…·жңүзӣҙжҺҘзҡ„жҢҮеҜјж„Ҹд№үгҖӮ

иҫ№зјҳи®Ўз®—дёӯвҖңж•°жҚ®вҖқдёҺвҖңи®Ўз®—вҖқзҡ„е…ізі»
дёҠйқўпјҢжҲ‘们д»Һж•°жҚ®еӯҳеӮЁйңҖжұӮзҡ„з»ҙеәҰи®Ёи®әдәҶиҫ№зјҳи®Ўз®—зҡ„ж•ҙдҪ“жһ¶жһ„гҖӮеңЁиҫ№зјҳи®Ўз®—зҡ„жһ¶жһ„и®ҫи®ЎдёӯиҝҳжңүдёҖдёӘйҮҚиҰҒй—®йўҳпјҡж•°жҚ®жҳҜеҗҰеә”иҜҘи·ҹйҡҸи®Ўз®—пјҢе®һзҺ°вҖңз®—еҠӣеңЁе“ӘйҮҢпјҢж•°жҚ®е°ұ移еҠЁеҲ°е“ӘйҮҢвҖқпјҹиҝҳжҳҜи®Ўз®—и·ҹзқҖж•°жҚ®иө°пјҢе®һзҺ°вҖңж•°жҚ®еӯҳж”ҫеңЁе“ӘйҮҢпјҢе°ұеңЁе“ӘйҮҢи®Ўз®—вҖқпјҹ
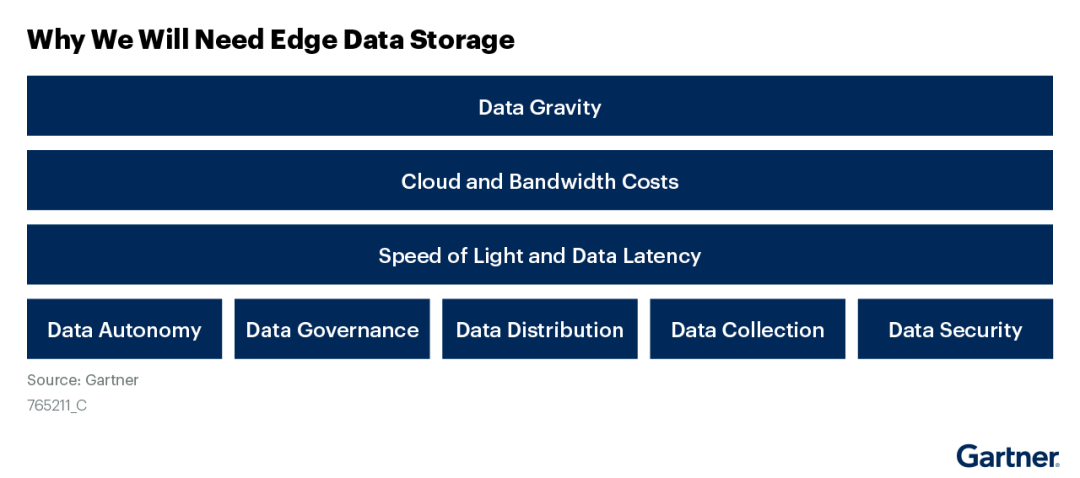
Gartner еңЁгҖҠInnovation Insight: Rethink Your Enterprise Storage and Cloud Data Services Strategies for the Edge AwakeningгҖӢдёӯпјҢжҺўи®ЁдәҶиҫ№зјҳи®Ўз®—дёӯеӯҳеӮЁж•°жҚ®зҡ„йңҖжұӮпјҢдҫӢеҰӮж•°жҚ®еј•еҠӣгҖҒж•°жҚ®дё»жқғгҖҒж•°жҚ®иҮӘжІ»гҖҒж•°жҚ®ж”¶йӣҶгҖҒж•°жҚ®еҲҶеҸ‘гҖҒж•°жҚ®е®үе…Ёзӯүеҗ„дёӘж–№йқўгҖӮ
еңЁиҫ№зјҳеә”з”ЁдёӯпјҢйңҖиҰҒе°Ҷж•°жҚ®дҝқеӯҳжҲ–жҡӮеӯҳдәҺдёҚеҗҢзҡ„з«ҷзӮ№дҪҚзҪ®пјҢжқҘж»Ўи¶ідёҚеҗҢеә”з”ЁеңәжҷҜзҡ„иҰҒжұӮгҖӮз”ұдәҺж•°жҚ®дј иҫ“зҡ„йҖҹеәҰдёҠйҷҗе°ұжҳҜе…үйҖҹпјҢеӣ жӯӨи®Ўз®—з«Ҝи®ҝй—®ж•°жҚ®жәҗзҡ„延时дёҺдәҢиҖ…д№Ӣй—ҙзҡ„и·қзҰ»жҲҗжӯЈжҜ”пјҢиҖҢеӨ„зҗҶж•°жҚ®зҡ„延时дёҺеӨ„зҗҶз®—жі•зҡ„еӨҚжқӮеәҰжӯЈзӣёе…ігҖӮиҝҷдёӨйЎ№пјҢзү№еҲ«жҳҜй•ҝи·қзҰ»иҜ»еҶҷж•°жҚ®иҖ—иҙ№зҡ„ж—¶й—ҙпјҢеңЁиҫ№зјҳи®Ўз®—зҡ„жҜҸдёҖж¬Ўе“Қеә”жүҖйңҖзҡ„жҖ»ж—¶й•ҝдёӯеҚ дәҶеҫҲеӨ§жҜ”дҫӢгҖӮеӣ жӯӨпјҢз”ЁдәҺж”ҜжҢҒ延иҝҹй«ҳж•Ҹж„ҹеә”з”Ёзҡ„ж•°жҚ®пјҢеә”еңЁжңҖйқ иҝ‘иҫ№зјҳи®ҫеӨҮзҡ„дҪҚзҪ®иҝӣиЎҢе®һж—¶еҲҶжһҗе’ҢеӨ„зҗҶпјҢд»ҘжңҖеӨ§йҷҗеәҰең°зј©зҹӯж•°жҚ®иҜ»еҶҷ延时пјӣиҖҢз”ЁдәҺж”ҜжҢҒ延иҝҹдёҚж•Ҹж„ҹеә”з”Ёзҡ„ж•°жҚ®пјҢеҲҷеҸҜд»ҘйӣҶдёӯеӯҳж”ҫеңЁи·қзҰ»жӣҙиҝңгҖҒдҪҶеӯҳеӮЁе®№йҮҸжӣҙеӨ§гҖҒеӯҳеӮЁжҠҖжңҜжӣҙеҠ е®Ңе–„зҡ„ж•°жҚ®дёӯеҝғпјҢд»Ҙе®һзҺ°жӣҙдҪҺзҡ„еӯҳеӮЁжҲҗжң¬е’Ңжӣҙй«ҳзҡ„еӯҳеӮЁе®үе…ЁжҖ§гҖӮ
иҫ№зјҳи®ҫеӨҮиҺ·еҸ–зҡ„еҺҹе§Ӣж•°жҚ®пјҢеҸҜиғҪжңүдёҚеҗҢзҡ„еӨ„зҗҶж–№ејҸпјҡ
ж— еӨ„зҗҶпјҡж•°жҚ®зӣҙжҺҘд»Һи®ҫеӨҮйҮҮйӣҶеҗҺпјҢдёҚз»ҸиҝҮд»»дҪ•еӨ„зҗҶпјҢеҺҹж ·дҝқеӯҳгҖӮ
йў„еӨ„зҗҶпјҡж•°жҚ®еңЁи®ҫеӨҮз«ҜиҝӣиЎҢеҲқжӯҘеӨ„зҗҶпјҢеҰӮжё…жҙ—гҖҒж јејҸиҪ¬жҚўгҖҒејӮеёёеҖјжЈҖжөӢзӯүпјҢ然еҗҺдҝқеӯҳеӨ„зҗҶеҗҺзҡ„ж•°жҚ®гҖӮ
е®һж—¶еӨ„зҗҶпјҡж•°жҚ®еңЁи®ҫеӨҮз«ҜиҝӣиЎҢе®һж—¶еҲҶжһҗе’ҢеӨ„зҗҶпјҢдҫӢеҰӮе®һж—¶з»ҹи®ЎгҖҒиҒҡеҗҲзӯүпјҢеҸӘдҝқеӯҳеӨ„зҗҶеҗҺзҡ„жҰӮиҰҒдҝЎжҒҜгҖӮ
延иҝҹеӨ„зҗҶпјҡе…Ғи®ёеҜ№ж•°жҚ®иҝӣиЎҢеҮҶе®һж—¶жҲ–ејӮжӯҘеӨ„зҗҶпјҢеҰӮжҜҸеҲҶй’ҹгҖҒжҜҸе°Ҹж—¶гҖҒжҜҸеӨ©зӯүпјҢ然еҗҺдҝқеӯҳеӨ„зҗҶеҗҺзҡ„з»“жһңгҖӮ
еҜ№дәҺз»ҸиҝҮд»ҘдёҠдёҚеҗҢж–№ејҸеӨ„зҗҶзҡ„ж•°жҚ®пјҢеҸҜд»ҘйҖүжӢ©иҝӣиЎҢжң¬ең°жҡӮеӯҳпјҲеҚ•еүҜжң¬гҖҒж— дҝқйҡңпјүгҖҒдә‘з«Ҝ/ж•°жҚ®дёӯеҝғйӣҶдёӯеӯҳеӮЁгҖҒеҲҶеёғејҸеӯҳеӮЁпјҢжҲ–иҝҷдёүз§Қж–№ејҸзҡ„ж··еҗҲгҖӮйңҖиҰҒй•ҝжңҹдҝқеӯҳзҡ„ж•°жҚ®пјҢж—ўиҰҒиҖғиҷ‘е…¶дҪҝз”Ёйў‘зҺҮгҖҒдёҺиҫ№зјҳи®ҫеӨҮзҡ„зӣёеҜ№дҪҚзҪ®е…ізі»пјҢд№ҹиҰҒиҖғиҷ‘еӯҳеӮЁзҡ„е®№йҮҸгҖҒжү©еұ•жҖ§гҖҒеҸҜз”ЁжҖ§гҖҒе®үе…ЁжҖ§гҖҒжүҖжңүжқғгҖҒжі„жјҸйЈҺйҷ©е’Ңз»јеҗҲжҲҗжң¬гҖӮиҝҷе°ұжҳҜ GartnerвҖңиҫ№зјҳж•°жҚ®еӯҳеӮЁвҖқжҠҘе‘Ҡдёӯзҡ„дё»иҰҒи§ӮзӮ№гҖӮ
з”ұд»ҘдёҠеҜ№ж•°жҚ®е’ҢеӯҳеӮЁзү№зӮ№зҡ„еҲҶжһҗеҫ—еҮәз»“и®әпјҡеә”иҜҘжҳҜвҖңи®Ўз®—и·ҹзқҖж•°жҚ®вҖқиө°гҖӮеӣ дёәйҖүжӢ©ж•°жҚ®зҡ„еӯҳж”ҫдҪҚзҪ®дёҺдҝқеӯҳжҠҖжңҜпјҢж¶үеҸҠеҲ°з«ҷзӮ№зҡ„иҪҜ硬件жһ¶жһ„пјҢеҜ№з«ҷзӮ№жһ¶жһ„иҝӣиЎҢеҸҳеҠЁзҡ„е‘Ёжңҹй•ҝгҖҒжҲҗжң¬й«ҳпјӣиҖҢ且移еҠЁж•°жҚ®жҳҜдёҖ件зӣёеҜ№еӣ°йҡҫзҡ„е·ҘдҪңпјҢеңЁдёҚеҗҢзү©зҗҶд»ӢиҙЁдёӯдј иҫ“йңҖиҰҒеӨ§йҮҸзҡ„ж—¶й—ҙпјҢд№ҹеҫҲйҡҫдҝқиҜҒеңЁд»»дҪ•иҫ№зјҳз«ҷзӮ№йғҪжңүи¶іеӨҹзҡ„еӯҳеӮЁз©әй—ҙз”ЁдәҺеӯҳж”ҫд»Һе…¶д»–з«ҷзӮ№з§»еҠЁиҝҮжқҘзҡ„ж•°жҚ®гҖӮд»ҘдёҠдёӨж–№йқўеҜ№иҫ№зјҳеә”з”Ёзҡ„дҪҝз”Ёж•Ҳжһңе’ҢжҲҗжң¬жңүзӣҙжҺҘеҪұе“ҚгҖӮ
вҖңи®Ўз®—и·ҹзқҖж•°жҚ®иө°вҖқеҸӘжҳҜдёҖз§ҚйҖҡдҝ—зҡ„иҜҙжі•пјҢжҢҮзҡ„жҳҜе°Ҷзү№е®ҡзҡ„з®—жі•/зЁӢеәҸеҲҶеҸ‘еҲ°дёҚеҗҢзҡ„иҫ№зјҳдҪҚзҪ®пјҢд»Ҙдҫҝеҝ«йҖҹең°гҖҒе®үе…Ёең°еңЁеҪ“ең°еӨ„зҗҶж•°жҚ®пјҢеҸҜд»ҘеҮҸе°‘ж•°жҚ®дј иҫ“зҡ„延иҝҹгҖҒйҷҚдҪҺж•°жҚ®еңЁеӨҡең°еӯҳеӮЁзҡ„жҲҗжң¬гҖӮиҝҷйҮҢзҡ„вҖңи®Ўз®—вҖқпјҢжҢҮзҡ„жҳҜз®—жі•жҲ–зЁӢеәҸпјҢеӣ дёәжҜҸз§Қеә”з”ЁйңҖиҰҒзү№е®ҡзҡ„з®—жі•жқҘеӨ„зҗҶзү№е®ҡзҡ„ж•°жҚ®гҖӮд»Һж•°жҚ®дёӯеҝғзҡ„еә”з”Ёеә“дёӯеҲҶеҸ‘еҲ°иҫ№зјҳзҡ„пјҢеҸҜиғҪжҳҜ 1 дёӘ Function жҲ–иҖ…дёҖдёӘе°ҸзЁӢеәҸпјҢиҝҷе°ұжҳҜеүҚйқўжҸҗеҲ°зҡ„вҖңи®Ўз®—и·ҹзқҖж•°жҚ®иө°вҖқгҖӮз®—жі•/зЁӢеәҸзҡ„ж–Ү件е°әеҜёдёҺеә”з”Ёж•°жҚ®зӣёжҜ”еҸҜд»ҘиҜҙжҳҜвҖңиҪ»еҰӮеҫ®е°ҳвҖқпјҢйҖӮеҗҲдәҺиў«еҝ«йҖҹең°еҲҶеҸ‘еҲ°еҗ„з§ҚдёҚеҗҢзҡ„з«ҷзӮ№пјҢеңЁз«ҷзӮ№дёҠд»ҘиҷҡжӢҹеҢ–жҲ–е®№еҷЁеҢ–еҪўжҖҒдҪҝз”ЁеҪ“ең°зҡ„и®Ўз®—иө„жәҗжұ гҖҒеӨ„зҗҶеҪ“ең°дҝқеӯҳзҡ„ж•°жҚ®гҖҒеҝ«йҖҹе“Қеә”еҪ“ең°зҡ„еә”з”ЁиҜ·жұӮгҖӮ
йӮЈд№Ҳй—®йўҳжқҘдәҶпјҡиҝҷз§Қж–№ејҸдёӢпјҢеңЁжҜҸдёӘиҫ№зјҳдҪҚзҪ®дёҠжҳҜеҗҰжңүи¶іеӨҹзҡ„и®Ўз®—иө„жәҗд»Ҙдҫӣеҗ„з§Қз®—жі•/зЁӢеәҸдҪҝз”Ёе‘ўпјҹе®һйҷ…дёҠпјҢеӨ§йғЁеҲҶиҫ№зјҳз«ҷзӮ№е№¶дёҚзјәи®Ўз®—иө„жәҗгҖӮеңЁиҝҮеҺ»еҚҒеӨҡе№ҙзҡ„иҷҡжӢҹеҢ–е®һи·өе’Ңиҝ‘е№ҙе®№еҷЁеҢ–е®һи·өдёӯзңӢеҲ°зҡ„жҷ®йҒҚзҺ°иұЎжҳҜпјҢеҗ„з§Қдә‘гҖҒж•°жҚ®дёӯеҝғгҖҒеҲҶж”Ҝз«ҷзӮ№зҡ„ CPU иө„жәҗжҖ»дҪ“дёҠжҳҜе……и¶ізҡ„гҖӮе®һзҺ°вҖңи®Ўз®—и·ҹзқҖж•°жҚ®иө°вҖқпјҢ并дёҚж„Ҹе‘ізқҖиҰҒе°ҶдёҖдёӘз«ҷзӮ№зҡ„硬件 CPU дёҙж—¶иҝҒ移еҲ°е…¶д»–з«ҷзӮ№гҖӮ
иҫ№зјҳз«ҷзӮ№зҡ„жҠҖжңҜйңҖжұӮ
ж №жҚ®д»ҘдёҠеҲҶжһҗпјҢжҲ‘们жҖ»з»“дәҶиҫ№зјҳз«ҷзӮ№еҜ№и®Ўз®—гҖҒеӯҳеӮЁгҖҒзҪ‘з»ңзӯүеҹәзЎҖжһ¶жһ„еұӮйқўзҡ„жҠҖжңҜйңҖжұӮгҖӮ

е·Ұдҫ§зҡ„дёүдёӘжҠҖжңҜйңҖжұӮпјҢеңЁдёҚеҗҢзҡ„иҫ№зјҳз«ҷзӮ№дёҠеҸҜиғҪеӯҳеңЁе·®ејӮпјҡеӣ дёәжҜҸдёӘз«ҷзӮ№йқўеҗ‘зҡ„е®ўжҲ·зҫӨгҖҒжүҖеңЁең°зҗҶдҪҚзҪ®йғҪдёҚзӣёеҗҢпјҢжҜҸз§Қиҫ№зјҳеә”з”Ёзҡ„и®Ўз®—йңҖжұӮгҖҒеӯҳеӮЁйңҖжұӮе’Ң延иҝҹйңҖжұӮйғҪдёҚеҗҢгҖӮдҪҶд№ҹеҸҜд»Һдёӯеҫ—еҮәз»“и®әпјҡеј№жҖ§е’Ңе…је®№жҳҜиҫ№зјҳз«ҷзӮ№еҹәзЎҖжһ¶жһ„еҝ…еӨҮзҡ„зү№зӮ№пјҢеҸӘжңүеј№жҖ§е’Ңе…је®№зҡ„жһ¶жһ„жүҚиғҪзҒөжҙ»ең°йҖӮеә”еҗ„з§Қ规模гҖҒеҗ„з§Қзұ»еһӢзҡ„еә”з”ЁгҖӮ
еҸідҫ§зҡ„дёүдёӘиҰҒзҙ еҲҷжҳҜжӣҙдёәйҖҡз”Ёзҡ„йңҖжұӮпјҢд»»дҪ•дёәиҫ№зјҳеә”з”Ёжһ„е»әзҡ„еҹәзЎҖжһ¶жһ„дҪ“зі»дёӯпјҢжҷ®йҒҚйңҖиҰҒйӣҶдёӯжҺ§еҲ¶гҖҒж··еҗҲеә”з”ЁиҙҹиҪҪпјҲз®—жі•/зЁӢеәҸпјүзҡ„йӣҶдёӯз®ЎзҗҶе’ҢжҢүйңҖеҲҶеҸ‘пјҢд»ҘеҸҠеңЁжҜҸдёӘз«ҷзӮ№дёҠи®ҫзҪ®е®үе…ЁжңәеҲ¶жқҘдҝқйҡңеҶ…йғЁж•°жҚ®е’ҢеӨ–йғЁи®ҝй—®зҡ„е®үе…ЁжҖ§гҖӮ
йҮҚзӮ№йңҖжұӮпјҡйҖӮеә”еә”з”Ёж··еҗҲйғЁзҪІ
еңЁиҝҷйҮҢйңҖиҰҒзү№еҲ«ејәи°ғдёҖзӮ№пјҢеҚіж··еҗҲйғЁзҪІеңЁиҫ№зјҳеә”з”Ёдёӯзҡ„ж„Ҹд№үгҖӮж··еҗҲйғЁзҪІжҢҮзҡ„жҳҜд»ҘдёҚеҗҢзҡ„еҪўжҖҒеҺ»жүҝиҪҪиҫ№зјҳеә”з”ЁпјҢдҫӢеҰӮиҷҡжӢҹеҢ–жҲ–е®№еҷЁеҢ–зҡ„еҪўжҖҒгҖӮд»ҠеҗҺпјҢеҸҜиғҪдјҡеҮәзҺ°жӣҙз»Ҷйў—зІ’еәҰзҡ„йғЁзҪІж–№ејҸиҝҗиЎҢдёҚеҗҢиҫ№зјҳеә”з”ЁжҲ–е…¶дёӯзҡ„еҠҹиғҪгҖӮ
ејәи°ғеә”з”Ёзҡ„ж··еҗҲйғЁзҪІпјҢжҳҜеӣ дёәиҫ№зјҳеә”з”Ёж•°йҮҸеҝ«йҖҹеўһеҠ пјҢе…¶дёӯдёҚд№Ҹдё“й—Ёдёәиҫ№зјҳеңәжҷҜејҖеҸ‘зҡ„гҖҒеҸҜз§°д№ӢдёәвҖңиҫ№зјҳеҺҹз”ҹвҖқзҡ„еә”з”ЁгҖӮдҪҶжҳҜд»Қжңүи®ёеӨҡиҫ№зјҳеә”з”Ёдҫқиө–дәҺдј з»ҹжҠҖжңҜе’Ңж–№жі•пјҢдҫӢеҰӮе·Із»ҸеңЁиҷҡжӢҹеҢ–жҲ–е®№еҷЁеҢ–зҺҜеўғдёӯиҝҗиЎҢиүҜеҘҪзҡ„еҲҶеёғејҸж•°жҚ®еә“гҖҒж¶ҲжҒҜйҳҹеҲ—гҖҒдёӯй—ҙ件зЁӢеәҸгҖӮиҫ№зјҳеә”з”ЁејҖеҸ‘иҖ…жҳҜеҗҰйңҖиҰҒдё“й—ЁдёәжңҖиҫ№зјҳзҡ„еңәжҷҜи®ҫи®Ўдё“з”Ёзҡ„ж•°жҚ®еә“гҖҒдёӯй—ҙ件гҖҒж¶ҲжҒҜйҳҹеҲ—жҲ–其他组件пјҹиҝҷж ·ж— з–‘дјҡиҖ—иҙ№иҫ№зјҳеә”з”ЁејҖеҸ‘иҖ…зҡ„зІҫеҠӣгҖӮзҺ°еңЁиҫ№зјҳдёҡжҖҒеҸ‘еұ•йқһеёёеҝ«пјҢеә”йҒҝе…Қйҷ·е…ҘвҖңйҮҚеӨҚйҖ иҪ®еӯҗвҖқејҸзҡ„еҲӣж–°пјҢиҖҢжҳҜеҝ«йҖҹең°еҹәдәҺе·Іжңүзҡ„иҪҜ件/жҸ’件жһ„е»әж–°зҡ„еә”з”ЁпјҢиҝҷж ·жүҚиғҪеӨҹжӣҙеҝ«ең°жҺЁеҮәж–°дә§е“ҒпјҢжҠўеҚ еёӮеңәе…ҲжңәпјҢд»ҺиҖҢиҺ·еҫ—жӣҙеӨ§зҡ„е•Ҷдёҡд»·еҖјгҖӮ
еӣ жӯӨвҖңиҫ№зјҳеҺҹз”ҹвҖқзҡ„ж–°еә”з”Ё/зЁӢеәҸе’Ңдј з»ҹеә”з”Ё/组件/жҸ’件дјҡеңЁиҫ№зјҳз«ҷзӮ№дёҠж··еҗҲеӯҳеңЁпјҢиҝҷиҰҒжұӮиҫ№зјҳи®Ўз®—дҪ“зі»е…·еӨҮиғҪеӨҹдёәиҝҷдәӣдёҚеҗҢзҡ„еә”з”ЁеҪўжҖҒжҸҗдҫӣз»ҹдёҖзҡ„ж”ҜжҢҒе’Ңи°ғеәҰеҲҶеҸ‘иғҪеҠӣгҖӮ
и¶…иһҚеҗҲпјҡж”ҜжҢҒиҫ№зјҳеә”з”Ёзҡ„зҗҶжғіжһ¶жһ„
еңЁеҲҶжһҗдәҶиҫ№зјҳеә”з”Ёзҡ„зү№зӮ№д»ҘеҸҠиҫ№зјҳз«ҷзӮ№зҡ„жҠҖжңҜйңҖжұӮеҗҺпјҢжҲ‘们и®ӨдёәпјҢи¶…иһҚеҗҲпјҲHCIпјүжҳҜзҺ°йҳ¶ж®өйқһеёёйҖӮеҗҲз”ЁжқҘж”ҜжҢҒиҫ№зјҳз«ҷзӮ№дёҠзҡ„еҗ„з§Қиҫ№зјҳеә”з”Ёзҡ„жһ¶жһ„е№іеҸ°пјҡи¶…иһҚеҗҲеҸҜд»ҘдёәеӨ§йғЁеҲҶиҫ№зјҳеә”з”ЁпјҲйҷӨдәҶеҝ…йЎ»иҝҗиЎҢеңЁвҖңиҝңз«Ҝиҫ№зјҳвҖқжҲ–вҖңи®ҫеӨҮиҫ№зјҳвҖқз«ҷзӮ№зҡ„еә”з”ЁпјүжҸҗдҫӣй«ҳжҖ§иғҪгҖҒеҸҜйқ е’ҢзЁіе®ҡзҡ„иҝҗиЎҢзҺҜеўғпјҢ并з®ҖеҢ–й…ҚзҪ®дҫӣеә”пјҲProvisioningпјүгҖҒиҝҗиҗҘе’Ңз®ЎзҗҶпјҢд»ҺиҖҢжҸҗй«ҳиҫ№зјҳеә”з”Ёзҡ„дәӨд»ҳж•ҲзҺҮгҖҒйҷҚдҪҺиҫ№зјҳи®Ўз®—зҡ„жҖ»дҪ“жӢҘжңүжҲҗжң¬пјҲTCOпјүгҖӮ
и¶…иһҚеҗҲеҹәзЎҖжһ¶жһ„зҡ„жҲҗзҶҹеәҰжҳҜе…¶йҖӮз”ЁдәҺжүҝиҪҪиҫ№зјҳеә”з”Ёзҡ„жңҖдё»иҰҒеҺҹеӣ гҖӮGartner дәҺ 2022 е№ҙеҸ‘еёғзҡ„жҠҖжңҜжҲҗзҶҹеәҰжӣІзәҝпјҲHype CycleпјүжҳҫзӨәпјҢи¶…иһҚеҗҲжҠҖжңҜе’Ңдә§е“Ғе·Іиҝӣе…ҘзЁіе®ҡе№іеҸ°жңҹпјҢдё”з»ҸиҝҮи¶іеӨҹзҡ„жөӢиҜ•е’Ңз”ҹдә§жЎҲдҫӢйӘҢиҜҒпјҢи¶…иһҚеҗҲиғҪеӨҹеңЁз”ҹдә§зҺҜеўғдёӯжүҝиҪҪеҢ…жӢ¬иҫ№зјҳеңЁеҶ…зҡ„з»қеӨ§еӨҡж•°еә”з”ЁеҪўжҖҒгҖӮIDC еңЁ Hyperconverged Infrastructure Use Will Continue to Grow in Edge Environments з ”з©¶дёӯд№ҹиЎЁзӨәпјҡвҖңе°ҶиҷҡжӢҹеҢ–гҖҒи®Ўз®—гҖҒеӯҳеӮЁе’ҢзҪ‘з»ңжҠҖжңҜж•ҙеҗҲеҲ°еҚ•дёӘзі»з»ҹдёӯзҡ„и¶…иһҚеҗҲеҹәзЎҖжһ¶жһ„зі»з»ҹпјҢеҸҜдёәеңЁиҫ№зјҳзҺҜеўғдёӯйқўдёҙ IT дәәе‘ҳй…ҚзҪ®жҢ‘жҲҳзҡ„дјҒдёҡжҸҗдҫӣжҳҫи‘—дјҳеҠҝгҖӮе®ғ们жңүеҠ©дәҺз®ҖеҢ–дҫӣеә”гҖҒиҝҗиҗҘе’Ңз®ЎзҗҶпјҢ并еңЁе…·жңүжҲҗжң¬ж•ҲзӣҠзҡ„иЎҢдёҡж ҮеҮҶ硬件дёҠиҝҗиЎҢд»ҘйҷҚдҪҺжҲҗжң¬гҖӮвҖқеӣ жӯӨпјҢдјҒдёҡз”ЁжҲ·жҲ–иҫ№зјҳеә”з”ЁжҸҗдҫӣе•ҶеҸҜд»ҘеңЁеҹәзЎҖжһ¶жһ„ж–№жЎҲдёҠиҠӮзңҒеӨ§йҮҸзҡ„ж—¶й—ҙпјҢзӣҙжҺҘеҲ©з”Ёи¶…иһҚеҗҲжһ¶жһ„пјҢдёәеҗ„з§Қиҫ№зјҳеә”з”Ёеҝ«йҖҹжҸҗдҫӣж•ҙеҗҲдәҶеҗ„з§Қиө„жәҗзҡ„иҝҗиЎҢзҺҜеўғгҖӮ

жӯӨеӨ–пјҢи¶…иһҚеҗҲжһ¶жһ„зҡ„д»ҘдёӢзү№жҖ§д№ҹеҸҜе……еҲҶж»Ўи¶іиҫ№зјҳеә”з”ЁеңЁжҖ§иғҪгҖҒеј№жҖ§гҖҒж··еҗҲеә”з”Ёж”ҜжҢҒе’ҢйӣҶдёӯжҺ§еҲ¶зӯүж–№йқўзҡ„йңҖжұӮпјҡ
иҪҜ硬件解иҖҰпјҡи¶…иһҚеҗҲеҹәдәҺвҖңиҪҜ件е®ҡд№үвҖқзҡ„и®Ўз®—гҖҒеӯҳеӮЁе’ҢзҪ‘з»ңпјҢдҪҝеҫ—еҹәзЎҖи®ҫж–ҪдёҺ硬件и®ҫеӨҮеңЁе№ҝжіӣе…је®№зҡ„еҹәзЎҖдёҠе®һзҺ°дәҶе®Ңе…Ёи§ЈиҖҰгҖӮдёҺдј з»ҹжһ¶жһ„зӣёжҜ”пјҢи¶…иһҚеҗҲеҹәзЎҖжһ¶жһ„жүҖйңҖзҡ„дё“й—Ёи®ҫеӨҮж•°йҮҸжӣҙе°‘пјҢеҸҜд»ҘйҷҚдҪҺжҲҗжң¬гҖӮ
й«ҳжҖ§иғҪпјҡи¶…иһҚеҗҲж”ҜжҢҒжҢүйңҖй…ҚзҪ®дёҚеҗҢи§„ж јзҡ„ CPUгҖҒGPUгҖҒеӯҳеӮЁе’ҢзҪ‘з»ң组件пјҢд»Ҙж»Ўи¶ідёҚеҗҢеә”з”ЁеҜ№жҖ§иғҪзҡ„иҰҒжұӮпјҢж»Ўи¶іиҫ№зјҳи®Ўз®—еңәжҷҜдёӯзҡ„й«ҳжҖ§иғҪйңҖжұӮгҖӮ
жү©еұ•жҖ§пјҡи¶…иһҚеҗҲе…Ғи®ёд»Һе°Ҹ规模иө·жӯҘпјҢйҖҡиҝҮвҖңж ҮеҮҶжЁЎеқ—вҖқзҡ„ж–№ејҸеҝ«йҖҹжһ„е»әеӨҡдёӘиҫ№зјҳз«ҷзӮ№пјҢ并иғҪйҡҸж—¶жҢүйңҖжү©еұ•з«ҷзӮ№еҶ…зҡ„иө„жәҗ规模пјҢе®һзҺ°з®Җдҫҝзҡ„иө„жәҗжү©еұ•гҖӮ
йҖӮз”ЁжҖ§пјҡи¶…иһҚеҗҲжҸҗдҫӣеҜ№иҷҡжӢҹеҢ–е’Ңе®№еҷЁеҢ–еә”з”Ёзҡ„иө„жәҗж”Ҝж’‘е’Ңз®ЎзҗҶеҠҹиғҪпјҢйҖӮз”ЁдәҺеӨҡз§Қзұ»еһӢзҡ„иҝ‘з«Ҝиҫ№зјҳи®Ўз®—еә”з”ЁеңәжҷҜгҖӮ
жҳ“з®ЎзҗҶжҖ§пјҡи¶…иһҚеҗҲи§ЈеҶіж–№жЎҲе…Ғи®ёд»Һдёӯеҝғз«ҷзӮ№еҜ№еӨҡдёӘиҝңзЁӢз«ҷзӮ№иҝӣиЎҢеҸҜи§ҶеҢ–з®ЎзҗҶпјҢйҷҚдҪҺдәҶиҝҗз»ҙзҡ„еӨҚжқӮжҖ§пјҢжҸҗй«ҳдәҶз®ЎзҗҶж•ҲзҺҮгҖӮ

