




ж–°й—»иҜҰжғ…
ж–°й—»жҗңзҙў
жөӘжҪ® жңҚеҠЎеҷЁ-ејҖж”ҫеҠ йҖҹ规иҢғAIжңҚеҠЎеҷЁ и§ЈеҶіеӨ§жЁЎеһӢж—¶д»Јзҡ„еӨҡе…ғAIз®—еҠӣжҢ‘жҲҳ еӣӣе·қ жҲҗйғҪ 科жұҮ科жҠҖ ITжңҚеҠЎе•Ҷ
еҪ“еүҚпјҢвҖңзҷҫжЁЎеӨ§жҲҳвҖқеёҰжқҘдәҶз®—еҠӣйңҖжұӮзҡ„зҲҶеҸ‘пјҢAIиҠҜзүҮдә§дёҡд№ҹиҝҺжқҘе·ЁеӨ§жңәйҒҮпјҢвҖңеҲӣж–°жһ¶жһ„+ејҖжәҗз”ҹжҖҒвҖқжӯЈеңЁжҝҖеҸ‘еӨҡе…ғAIз®—еҠӣдә§е“ҒзҷҫиҠұйҪҗж”ҫгҖӮйқўеҜ№ж–°зҡ„дә§дёҡжңәдјҡпјҢAIз®—еҠӣдә§дёҡй“ҫдәҹйңҖйҖҡиҝҮдёҠдёӢжёёеҚҸдҪңе…ұеҗҢжҠҠжҸЎжңәйҒҮгҖӮ
в– в– ж—ҘеүҚпјҢеңЁејҖж”ҫи®Ўз®—дёӯеӣҪеі°дјҡOCP China Day 2023дёҠпјҢжөӘжҪ®дҝЎжҒҜAI&HPCдә§е“Ғзәҝй«ҳзә§дә§е“Ғз»ҸзҗҶStephen Zhangе°ұгҖҠејҖж”ҫеҠ йҖҹ规иҢғAIжңҚеҠЎеҷЁи®ҫи®ЎжҢҮеҚ—гҖӢиҝӣиЎҢдәҶдё“йўҳжҠҘе‘Ҡжј”и®ІпјҢеҲҶдә«дәҶAIGCж—¶д»Јзҡ„з®—еҠӣйңҖжұӮи¶ӢеҠҝдёҺејҖж”ҫеҠ йҖҹи®Ўз®—еҸ‘еұ•д№ӢйҒ“гҖӮд»–жҢҮеҮәпјҢд»Һзі»з»ҹеұӮйқўиҝӣиЎҢдә§дёҡй“ҫеҚҸеҗҢеҲӣж–°жҲҗдёәеҗҺж‘©е°”е®ҡеҫӢж—¶д»Јз ҙи§ЈAIGCз®—еҠӣжҢ‘жҲҳзҡ„еҝ…з»Ҹд№Ӣи·ҜгҖӮеҪ“еүҚпјҢејҖж”ҫеҠ йҖҹи®Ўз®—з”ҹжҖҒе·Із»ҸеңЁжӯӨж–№йқўеҸ–еҫ—дәҶдё°еҜҢжңүзӣҠзҡ„жҲҗжһңпјҢеӨҡе…ғзҡ„AIз®—еҠӣдә§е“ҒжӯЈеңЁеҠ йҖҹиҗҪең°пјҢдҝғиҝӣAIз®—еҠӣдә§дёҡ蓬еӢғеҸ‘еұ•гҖӮ
жј”и®ІиҰҒзӮ№пјҡ
в–җ еӨ§жЁЎеһӢеёҰжқҘеҜ№AIи®Ўз®—жҖ§иғҪгҖҒдә’иҒ”еёҰе®ҪгҖҒеҸҜжү©еұ•жҖ§зҡ„зҲҶеҸ‘ејҸйңҖжұӮпјӣ
в–җ ејҖж”ҫеҠ йҖҹи®Ўз®—жҠҖжңҜдёәеӨ§и§„жЁЎж·ұеәҰзҘһз»ҸзҪ‘з»ңи®ӯз»ғиҖҢз”ҹпјӣ
в–җ еә”з”ЁеҜјеҗ‘зҡ„з®—еҠӣеҹәзЎҖи®ҫж–Ҫжһ¶жһ„и®ҫи®Ўд»ҘеҸҠз®—еҠӣе’Ңз®—жі•зҡ„еҚҸеҗҢи®ҫи®ЎпјҢиғҪеӨҹе®һзҺ°жӣҙй«ҳж•Ҳзҡ„еӨ§жЁЎеһӢи®ӯз»ғпјӣ
в–җ ејҖж”ҫеҠ йҖҹи®Ўз®—еңЁжҖ§иғҪгҖҒжү©еұ•жҖ§гҖҒиҠӮиғҪгҖҒз”ҹжҖҒе…је®№еұӮйқўз§ҜзҙҜдәҶдё°зЎ•жҲҗжһңпјӣ
д»ҘдёӢдёәжј”и®ІеҺҹж–Үпјҡ
еӨ§жЁЎеһӢж—¶д»Јзҡ„з®—еҠӣйңҖжұӮеҸҠи¶ӢеҠҝ
иҮӘChatGPTеҸ‘еёғд»ҘжқҘпјҢеӨ§е®¶еҸҜд»ҘжҳҺжҳҫең°ж„ҹеҸ—еҲ°е…ЁзӨҫдјҡеҜ№дәҺз”ҹжҲҗејҸдәәе·ҘжҷәиғҪжҠҖжңҜзҡ„е№ҝжіӣе…іжіЁпјҢChatGPTеҮәеңҲд№ӢеҗҺеёҰжқҘдәҶжӣҙеӨҡеҸӮдёҺиҖ…пјҢжЁЎеһӢзҡ„ж•°йҮҸе’ҢжЁЎеһӢеҸӮж•°йҮҸдёҚж–ӯжҝҖеўһгҖӮжҚ®дёҚе®Ңе…Ёз»ҹи®ЎпјҢжҲ‘们еӣҪ家зҡ„еӨ§жЁЎеһӢж•°йҮҸе·Із»Ҹи¶…иҝҮ110дёӘпјҢиҝҷе°ұеёҰжқҘдәҶеҜ№дәҺAIз®—еҠӣйңҖжұӮзҡ„еү§еўһгҖӮ
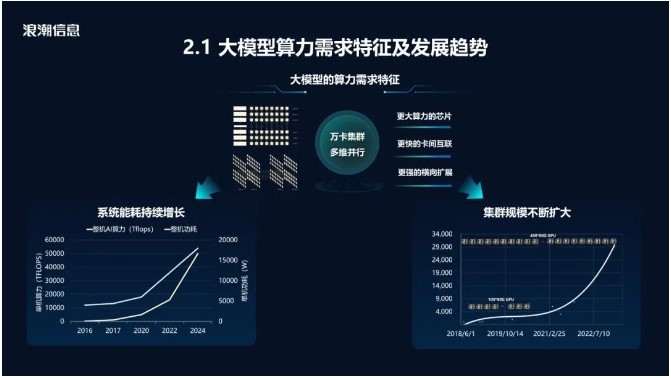
й’ҲеҜ№еӨ§жЁЎеһӢеҸ‘еұ•еёҰжқҘзҡ„дёҘеі»з®—еҠӣжҢ‘жҲҳпјҢжҲ‘们иҝӣиЎҢдәҶеӨ§йҮҸзҡ„йңҖжұӮеҲҶжһҗе’Ңи¶ӢеҠҝеҲӨж–ӯгҖӮд»ҺAIжңҚеҠЎеҷЁз®—еҠӣеҸҠеҠҹиҖ—йҡҸж—¶й—ҙеҸҳеҢ–зҡ„и¶ӢеҠҝжқҘзңӢпјҢиҰҒи§ЈеҶіеӨ§жЁЎеһӢзҡ„з®—еҠӣзҹӯзјәй—®йўҳпјҢжңҖзӣҙжҺҘзҡ„ж–№ејҸжҳҜжҸҗй«ҳеҚ•жңәзҡ„з®—еҠӣгҖӮд»Һ2016е№ҙеҲ°зҺ°еңЁпјҢAIжңҚеҠЎеҷЁеҚ•жңәз®—еҠӣеўһй•ҝиҝ‘100еҖҚпјҢеҠҹиҖ—д»Һ4еҚғз“Ұеўһй•ҝеҲ°12еҚғз“ҰпјҢдёӢдёҖд»ЈAIжңҚеҠЎеҷЁзҡ„еҠҹиҖ—继з»ӯеўһй•ҝеҲ°18еҚғз“Ұд№ғиҮі20еҚғз“Ұд»ҘдёҠгҖӮAIжңҚеҠЎеҷЁзҡ„зі»з»ҹжһ¶жһ„дҫӣз”өгҖҒж•Јзғӯж–№ејҸпјҢд»ҘеҸҠж•°жҚ®дёӯеҝғеҹәзЎҖи®ҫж–Ҫе»әи®ҫжЁЎејҸпјҢе°Ҷйҡҫд»Ҙж»Ўи¶іжңӘжқҘй«ҳеҠҹиҖ—AIжңҚеҠЎеҷЁзҡ„йғЁзҪІйңҖжұӮгҖӮ
е…¶ж¬ЎпјҢеӨ§жЁЎеһӢеҸӮж•°йҮҸеўһй•ҝеҜ№GPUж•°йҮҸзҡ„йңҖжұӮд№ҹйҡҸд№ӢеўһеҠ пјҢйңҖиҰҒжӣҙеӨ§зҡ„жҳҫеӯҳе®№йҮҸжүҝиҪҪгҖӮ2021е№ҙпјҢдёҖдёӘеҚғдәҝ规模зҡ„еӨ§жЁЎеһӢйңҖиҰҒ3,000 GBжҳҫеӯҳе®№йҮҸз©әй—ҙжүҝиҪҪпјҢжҚўз®—иҝҮжқҘйңҖиҰҒе°Ҷиҝ‘40еј 80Gзҡ„GPUжүҚиғҪж”ҫеҫ—дёӢиҝҷдёӘжЁЎеһӢпјҢеҢ…жӢ¬жқғйҮҚеҸӮж•°гҖҒжўҜеәҰж•°жҚ®гҖҒдјҳеҢ–еҖјж•°жҚ®е’ҢжҝҖжҙ»еҖјж•°жҚ®гҖӮд»ҠеӨ©пјҢеҫҲеӨҡеӨ§жЁЎеһӢзҡ„еҸӮж•°йҮҸе·Із»Ҹи¶…иҝҮдәҶдёҮдәҝ规模пјҢжҳҫеӯҳе®№йҮҸе°ҶдјҡиҫҫеҲ°30,000GBпјҢйңҖиҰҒе°Ҷиҝ‘400еқ—80Gжҳҫеӯҳзҡ„GPUжүҚиғҪжүҝиҪҪпјҢиҝҷж„Ҹе‘ізқҖйңҖиҰҒжӣҙеӨ§и§„жЁЎзҡ„з®—еҠӣе№іеҸ°жүҚиғҪиҝӣиЎҢеҰӮжӯӨ规模еӨ§жЁЎеһӢзҡ„и®ӯз»ғгҖӮ
жӣҙеӨ§и§„жЁЎзҡ„е№іеҸ°дјҡеёҰжқҘеҸҰеӨ–дёҖдёӘй—®йўҳпјҢеҚіеҚЎдёҺеҚЎд№Ӣй—ҙгҖҒдёҚеҗҢзҡ„иҠӮзӮ№д№Ӣй—ҙзҡ„жӣҙеӨҡйҖҡдҝЎпјҢеӨ§жЁЎеһӢзҡ„и®ӯз»ғйңҖиҰҒиһҚеҗҲеӨҡз§Қ并иЎҢзӯ–з•ҘпјҢеҜ№еҚЎй—ҙP2Pдә’иҒ”еёҰе®Ҫд»ҘеҸҠи·ЁиҠӮзӮ№дә’иҒ”еёҰе®ҪжҸҗеҮәдәҶжӣҙй«ҳзҡ„иҰҒжұӮгҖӮ
д»Ҙ2457дәҝеҸӮж•°зҡ„вҖңжәҗ1.0вҖқеӨ§жЁЎеһӢи®ӯз»ғзҡ„е·ҘзЁӢе®һи·өдёәдҫӢпјҢвҖңжәҗ1.0вҖқи®ӯз»ғе…ұжңү1800дәҝTokenпјҢжҳҫеӯҳе®№йҮҸйңҖжұӮ7.4TBпјҢи®ӯз»ғиҝҮзЁӢдёӯиһҚеҗҲдәҶеј йҮҸ并иЎҢгҖҒжөҒж°ҙзәҝ并иЎҢгҖҒж•°жҚ®е№¶иЎҢдёүз§Қзӯ–з•ҘгҖӮеҚ•иҠӮзӮ№еј йҮҸ并иЎҢйҖҡдҝЎйў‘ж¬ЎиҫҫеҲ°жҜҸз§’82.4ж¬ЎпјҢиҠӮзӮ№еҶ…йҖҡдҝЎеёҰе®ҪжңҖдҪҺйңҖжұӮиҫҫеҲ°194GB/sгҖӮи®Ўз®—иҠӮзӮ№еҶ…дјҡејҖеұ•жөҒж°ҙзәҝ并иЎҢпјҢи·ЁиҠӮзӮ№йҖҡдҝЎеёҰе®ҪиҫҫеҲ°26.8GB/sпјҢиҮіе°‘йңҖиҰҒ300GbpsйҖҡдҝЎеёҰе®ҪжүҚиғҪж»Ўи¶іжөҒж°ҙзәҝ并иЎҢи®ӯз»ғзҡ„еёҰе®ҪйңҖжұӮгҖӮеңЁи®ӯз»ғвҖңжәҗ1.0вҖқиҝҮзЁӢдёӯпјҢе®һйҷ…з”ЁеҲ°дёӨеј 200GbpsзҪ‘еҚЎиҝӣиЎҢи·ЁиҠӮзӮ№йҖҡдҝЎпјҢж•°жҚ®е№¶иЎҢйҖҡдҝЎйў‘ж¬ЎдҪҺдҪҶж•°жҚ®йҮҸеӨ§пјҢеёҰе®ҪйңҖжұӮиҮіе°‘иҰҒиҫҫеҲ°8.8GB/sпјҢеҚ•жңә400Gbpsзҡ„еёҰе®ҪеҸҜд»Ҙж»Ўи¶ігҖӮйҡҸзқҖжЁЎеһӢеҸӮж•°йҮҸиҝӣдёҖжӯҘеўһеҠ д»ҘеҸҠGPUз®—еҠӣзҡ„жҲҗеҖҚеўһеҠ пјҢжңӘжқҘйңҖиҰҒжӣҙй«ҳзҡ„дә’иҒ”еёҰе®ҪжүҚиғҪж»Ўи¶іжӣҙеӨ§и§„жЁЎжЁЎеһӢзҡ„и®ӯз»ғйңҖжұӮгҖӮ
ејҖж”ҫеҠ йҖҹи®Ўз®— дёәи¶…еӨ§и§„жЁЎж·ұеәҰзҘһз»ҸзҪ‘з»ңиҖҢз”ҹ
йқўеҗ‘AIGCеӨ§жЁЎеһӢи®ӯз»ғзҡ„и®Ўз®—зі»з»ҹйңҖиҰҒе…·еӨҮдёүдёӘдё»иҰҒзү№еҫҒпјҢдёҖжҳҜеӨ§з®—еҠӣпјҢдәҢжҳҜй«ҳдә’иҒ”пјҢдёүжҳҜејәжү©еұ•пјҢдј з»ҹзҡ„PCIe CEMеҪўжҖҒзҡ„еҠ йҖҹеҚЎеҫҲйҡҫж»Ўи¶ідёүдёӘзү№еҫҒйңҖжұӮпјҢеӣ жӯӨи¶ҠжқҘи¶ҠеӨҡзҡ„иҠҜзүҮеҺӮе•ҶйғҪејҖеҸ‘дәҶйқһPCIeеҪўжҖҒзҡ„еҠ йҖҹеҚЎгҖӮејҖж”ҫи®Ўз®—з»„з»ҮOCPеңЁ2019е№ҙеҸ‘еёғдәҶдё“й—Ёйқўеҗ‘еӨ§жЁЎеһӢи®ӯз»ғзҡ„еҠ йҖҹи®Ўз®—зі»з»ҹжһ¶жһ„пјҢж ёеҝғжҳҜUBBе’ҢOAMж ҮеҮҶпјҢзү№зӮ№жҳҜеӨ§з®—еҠӣгҖӮMezzжүЈеҚЎеҪўжҖҒзҡ„еҠ йҖҹеҷЁе…·еӨҮжӣҙй«ҳзҡ„ж•Јзғӯе’Ңдә’иҒ”иғҪеҠӣпјҢеҸҜд»ҘжүҝиҪҪе…·жңүжӣҙй«ҳз®—еҠӣзҡ„иҠҜзүҮгҖӮеҗҢж—¶пјҢе®ғжңүйқһеёёејәзҡ„и·ЁиҠӮзӮ№жү©еұ•иғҪеҠӣпјҢеҸҜд»ҘеҫҲиҪ»жҳ“ең°жү©еұ•еҲ°еҚғеҚЎгҖҒдёҮеҚЎзә§зҡ„е№іеҸ°пјҢж”Ҝж’‘еӨ§жЁЎеһӢзҡ„и®ӯз»ғгҖӮиҝҷдёӘжһ¶жһ„жҳҜеӨ©з„¶йҖӮз”ЁдәҺи¶…еӨ§и§„жЁЎж·ұеәҰзҘһз»ҸзҪ‘з»ңи®ӯз»ғзҡ„и®Ўз®—жһ¶жһ„гҖӮ

дҪҶжҳҜпјҢеңЁOAMдә§дёҡиҗҪең°иҝҮзЁӢдёӯпјҢеҫҲеӨҡеҺӮе•ҶжүҖејҖеҸ‘зҡ„еҠ йҖҹеҚЎдҫқ然еӯҳеңЁзЎ¬д»¶жҺҘеҸЈдёҚз»ҹдёҖгҖҒдә’иҒ”еҚҸи®®дёҚз»ҹдёҖпјҢеҗҢж—¶иҪҜ件з”ҹжҖҒдә’дёҚе…је®№пјҢеёҰжқҘдәҶж–°еһӢAIеҠ йҖҹеҚЎзі»з»ҹйҖӮй…Қе‘Ёжңҹй•ҝгҖҒе®ҡеҲ¶жҠ•е…ҘжҲҗжң¬й«ҳзҡ„иҗҪең°йҡҫйўҳпјҢеҜјиҮҙз®—еҠӣдҫӣз»ҷе’Ңз®—еҠӣйңҖжұӮд№Ӣй—ҙзҡ„еүӘеҲҖе·®дёҚж–ӯеҠ еӨ§пјҢиЎҢдёҡдәҹйңҖжӣҙеҠ ејҖж”ҫзҡ„з®—еҠӣе№іеҸ°пјҢд»ҘеҸҠжӣҙеҠ еӨҡе…ғзҡ„з®—еҠӣж”Ҝж’‘еӨ§жЁЎеһӢзҡ„и®ӯз»ғгҖӮеҜ№жӯӨпјҢжөӘжҪ®дҝЎжҒҜејҖеұ•дәҶеӨ§йҮҸе·ҘдҪңпјҢеҢ…жӢ¬жҠҖжңҜдёҠзҡ„йў„з ”е’ҢеҜ№дә§дёҡз”ҹжҖҒзҡ„иҙЎзҢ®гҖӮ2019е№ҙејҖе§ӢпјҢжөӘжҪ®дҝЎжҒҜзүөеӨҙдё»еҜјдәҶOAMж ҮеҮҶзҡ„еҲ¶е®ҡпјҢеҸ‘еёғдәҶйҰ–ж¬ҫејҖж”ҫеҠ йҖҹеҹәжқҝUBBпјҢеҗҢж—¶ејҖеҸ‘дәҶе…ЁзҗғйҰ–ж¬ҫејҖж”ҫеҠ йҖҹеҸӮиҖғзі»з»ҹMX1пјҢ并еҚҸеҗҢдёҡз•ҢйўҶе…Ҳзҡ„иҠҜзүҮеҺӮе•ҶдёҖиө·е®ҢжҲҗдәҶOAMеҪўжҖҒеҠ йҖҹеҚЎзҡ„йҖӮй…ҚпјҢиҜҒжҳҺдәҶиҝҷжқЎжҠҖжңҜи·Ҝзәҝзҡ„еҸҜиЎҢжҖ§гҖӮдёәдәҶжҺЁеҠЁз¬ҰеҗҲOAMејҖж”ҫеҠ йҖҹ规иҢғзҡ„зі»з»ҹдә§дёҡеҢ–иҗҪең°пјҢжөӘжҪ®дҝЎжҒҜејҖеҸ‘дәҶ第дёҖж¬ҫвҖңALL IN ONEвҖқ OAMжңҚеҠЎеҷЁдә§е“ҒпјҢжҠҠCPUе’ҢOAMеҠ йҖҹеҚЎйӣҶжҲҗеҲ°дёҖеҸ°19иӢұеҜёжңәз®ұдёӯпјҢе®һзҺ°ж•°жҚ®дёӯеҝғзә§зҡ„еҝ«йҖҹйғЁзҪІпјҢ并еңЁдј—еӨҡе®ўжҲ·зҡ„жҷәз®—дёӯеҝғиҗҪең°еә”з”ЁгҖӮ
жӯӨеҗҺпјҢOAM иҠҜзүҮзҡ„з®—еҠӣе’ҢеҠҹиҖ—еңЁдёҚж–ӯжҸҗеҚҮпјҢеҗҢж—¶ж•°жҚ®дёӯеҝғеҜ№дәҺз»ҝиүІиҠӮиғҪзҡ„иҰҒжұӮд№ҹи¶ҠжқҘи¶Ҡй«ҳгҖӮеҜ№жӯӨпјҢжҲ‘们ејҖеҸ‘дәҶ第дёҖж¬ҫж¶ІеҶ·OAMжңҚеҠЎеҷЁпјҢеҸҜд»Ҙе®һзҺ°8йў—OAMеҠ йҖҹеҷЁе’ҢдёӨйў—й«ҳеҠҹиҖ—зҡ„CPUзҡ„ж¶ІеҶ·ж•ЈзғӯпјҢж•ҙдёӘж¶ІеҶ·ж•ЈзғӯиҰҶзӣ–зҺҮи¶…иҝҮ90%пјҢеҹәдәҺиҝҷж¬ҫдә§е“Ғжһ„е»әзҡ„ж¶ІеҶ·OAMжҷәз®—дёӯеҝғи§ЈеҶіж–№жЎҲпјҢеҚғеҚЎе№іеҸ°зЁіе®ҡиҝҗиЎҢзҠ¶жҖҒдёӢPUEеҖје°ҸдәҺ1.1гҖӮиҖҢжөӘжҪ®дҝЎжҒҜеҲҡеҲҡеҸ‘еёғзҡ„ж–°дёҖд»Јзҡ„OAMжңҚеҠЎеҷЁNF5698G7пјҢеҹәдәҺе…ЁPCIe Gen5й“ҫи·ҜпјҢH2Dдә’иҒ”иғҪеҠӣжҸҗеҚҮ4еҖҚпјҢдёәж–°дёҖд»ЈOAMз ”еҸ‘жҸҗдҫӣдәҶжӣҙеҠ е…Ҳиҝӣзҡ„йғЁзҪІе№іеҸ°гҖӮ
йҖҡиҝҮе№іеҸ°жһ¶жһ„и®ҫи®Ўе’Ңз®—еҠӣз®—жі•еҚҸеҗҢи®ҫи®Ўи§ЈеҶіиғҪиҖ—й—®йўҳ
д»…д»…жҸҗдҫӣз®—еҠӣе№іеҸ°жҳҜдёҚеӨҹзҡ„пјҢзӣ®еүҚж•°жҚ®дёӯеҝғйқўдёҙзқҖе·ЁеӨ§зҡ„иғҪиҖ—жҢ‘жҲҳпјҢе°Өе…¶жҳҜйқўеҗ‘еӨ§жЁЎеһӢи®ӯз»ғзҡ„AIжңҚеҠЎеҷЁпјҢеҚ•жңәеҠҹиҖ—иҪ»жҳ“и¶…иҝҮ6-7еҚғз“ҰгҖӮ

дёҖдёӘе…¬ејҸеҸҜд»Ҙеҝ«йҖҹи®Ўз®—и®ӯз»ғдёҖдёӘеӨ§жЁЎеһӢжүҖйңҖиҰҒзҡ„ж•ҙдҪ“иҖ—з”өйҮҸпјҲEпјүпјҡеҲҶеӯҗз”Ё6еҖҚжЁЎеһӢеҸӮж•°йҮҸе’Ңи®ӯз»ғиҝҮзЁӢдёӯжүҖз”ЁеҲ°зҡ„Tokenж•°йҮҸиЎЁеҫҒеӨ§жЁЎеһӢи®ӯз»ғжүҖйңҖиҰҒзҡ„з®—еҠӣеҪ“йҮҸпјҢеҲҶжҜҚз”ЁеҠ йҖҹеҚЎзҡ„ж•°йҮҸиҝҳжңүеҚ•еј еҠ йҖҹеҚЎзҡ„з®—еҠӣжҖ§иғҪиЎЁеҫҒжҷәз®—еҹәзЎҖи®ҫж–ҪжүҖиғҪеӨҹжҸҗдҫӣзҡ„ж•ҙдҪ“з®—еҠӣжҖ§иғҪпјҢдәҢиҖ…зӣёйҷӨзҡ„з»“жһңд»ЈиЎЁзҡ„жҳҜи®ӯз»ғеӨ§жЁЎеһӢжүҖйңҖиҰҒзҡ„ж—¶й—ҙпјҢд№ҳд»ҘEclusterжҢҮж ҮпјҲеӨ§жЁЎеһӢи®ӯз»ғе№іеҸ°жҜҸж—ҘиҖ—з”өйҮҸпјүеҚіеҸҜеҫ—еҲ°ж•ҙдҪ“иҖ—з”өйҮҸгҖӮйӮЈд№ҲпјҢеңЁйҖүе®ҡжЁЎеһӢ并且жңүзЎ®е®ҡеҚЎж•°е’Ң规模зҡ„жғ…еҶөдёӢпјҢеҸӘжңүйҖҡиҝҮдјҳеҢ–еҚ•еҚЎз®—еҠӣеҖјпјҢжҲ–иҖ…йҷҚдҪҺеҚ•дёӘе№іеҸ°зҡ„иҖ—з”өйҮҸпјҢжүҚиғҪдјҳеҢ–еӨ§жЁЎеһӢи®ӯз»ғжүҖйңҖзҡ„ж•ҙдҪ“иҖ—з”өйҮҸгҖӮй’ҲеҜ№иҝҷдёӨдёӘеҸӮж•°зҡ„дјҳеҢ–пјҢжҲ‘们еҜ№дёҚеҗҢеӨ§жЁЎеһӢи®ӯз»ғе№іеҸ°зҪ‘з»ңжһ¶жһ„и®ҫи®ЎдёӢпјҢе№іеҸ°еҠҹиҖ—е’Ңзӣёеә”зҡ„еӨ§жЁЎеһӢи®ӯз»ғж•ҙдҪ“еҠҹиҖ—иҝӣиЎҢдәҶеҜ№жҜ”з ”з©¶гҖӮд»ҘеҚ•жңә2еј зҪ‘еҚЎпјҲNICпјүз»„зҪ‘ж–№жЎҲе’ҢеҚ•жңә8еј зҪ‘еҚЎпјҲNICпјүз»„зҪ‘ж–№жЎҲдёәдҫӢпјҢиҷҪ然дёҚеҗҢзҪ‘еҚЎж•°йҮҸеёҰжқҘзҡ„еҚ•жңәеҠҹиҖ—еҪұе“Қ并дёҚжҳҫи‘—пјҢ然иҖҢж”ҫеҲ°ж•ҙдёӘи®Ўз®—е№іеҸ°еұӮйқўпјҢзҪ‘еҚЎж•°йҮҸеўһеҠ еҜјиҮҙдәӨжҚўжңәж•°йҮҸеўһеҠ пјҢжҖ»еҠҹиҖ—дјҡжңүжҳҫи‘—е·®ејӮпјҢ8зҪ‘еҚЎж–№жЎҲжҖ»еҠҹиҖ—еҸҜиҫҫ2000еӨҡеҚғз“ҰпјҢ2зҪ‘еҚЎж–№жЎҲеҸӘжңү1600еӨҡеҚғз“ҰпјҢ2еј зҪ‘еҚЎж–№жЎҲеҸҜд»ҘиҠӮзңҒеҠҹиҖ—18%гҖӮ
еӣ жӯӨпјҢйқўеҗ‘е®һйҷ…еә”з”ЁйңҖжұӮпјҢйҖҡиҝҮзІҫз»ҶеҢ–ең°и®Ўз®—еӨ§жЁЎеһӢи®ӯз»ғжүҖйңҖиҰҒзҡ„зҪ‘з»ңеёҰе®ҪпјҢеҸҜд»ҘеңЁдёҚеҪұе“ҚжҖ§иғҪзҡ„еүҚжҸҗдёӢпјҢжҳҫи‘—ең°дјҳеҢ–жҖ»еҠҹиҖ—гҖӮвҖңжәҗвҖқеӨ§жЁЎеһӢи®ӯз»ғиҝҮзЁӢеҪ“дёӯпјҢд»…д»…дҪҝз”ЁдәҶдёӨеј 200Gзҡ„IBеҚЎе°ұе®ҢжҲҗ2457дәҝеҸӮж•°жЁЎеһӢзҡ„и®ӯз»ғпјҢиҝҷжҳҜжҲ‘们еҸ‘зҺ°зҡ„第дёҖдёӘдјҳеҢ–и®ӯз»ғе№іеҸ°жҖ»еҠҹиҖ—зҡ„жҠҖжңҜи·Ҝеҫ„гҖӮ
第дәҢпјҢжҸҗй«ҳеҚ•еҚЎз®—еҠӣеҲ©з”ЁзҺҮд»Ҙе®һзҺ°жҸҗж•ҲиҠӮиғҪпјҢд№ҹжҳҜйқһеёёйҮҚиҰҒзҡ„дёҖдёӘе‘ҪйўҳгҖӮз»ҸжҲ‘们жөӢиҜ•пјҢйҮҮз”Ёз®—жі•е’Ңз®—еҠӣжһ¶жһ„еҚҸеҗҢи®ҫи®Ўзҡ„ж–№жі•пјҢеҹәдәҺз®—еҠӣеҹәзЎҖи®ҫж–Ҫзҡ„жҠҖжңҜзү№зӮ№пјҢж·ұеәҰдјҳеҢ–жЁЎеһӢзҡ„еҸӮж•°з»“жһ„е’Ңи®ӯз»ғзӯ–з•ҘпјҢеҸҜд»Ҙз”Ёжӣҙзҹӯзҡ„ж—¶й—ҙе®ҢжҲҗеҗҢзӯү规模模еһӢзҡ„и®ӯз»ғгҖӮд»ҘGPT-3жЁЎеһӢзҡ„и®ӯз»ғдёәдҫӢпјҢжЁЎеһӢи®ӯз»ғж—¶й—ҙеҸҜд»Ҙд»Һ15еӨ©дјҳеҢ–дёә12еӨ©пјҢжҖ»иҖ—з”өйҮҸиҠӮзңҒиҫҫеҲ°33%гҖӮ
д»ҘдёҠдёӨзӮ№еҸҜд»ҘиҜҙжҳҺпјҢеә”з”ЁеҜјеҗ‘зҡ„жһ¶жһ„и®ҫи®ЎпјҢд»ҘеҸҠз®—еҠӣе’Ңз®—жі•зҡ„еҚҸеҗҢи®ҫи®ЎпјҢиғҪеӨҹе®һзҺ°жӣҙй«ҳж•Ҳзҡ„еӨ§жЁЎеһӢи®ӯз»ғпјҢжңҖз»ҲеҠ йҖҹиҠӮиғҪйҷҚзўізӣ®ж Үзҡ„е®һзҺ°гҖӮ
з»ҝиүІејҖж”ҫеҠ йҖҹе№іеҸ°пјҢиөӢеҠӣеӨ§жЁЎеһӢй«ҳж•ҲйҮҠж”ҫз®—еҠӣ
еҹәдәҺдёҠиҝ°еңЁејҖж”ҫи®Ўз®—гҖҒй«ҳж•Ҳи®Ўз®—зҡ„жҠҖжңҜгҖҒдә§е“Ғе’Ңж–№жі•зҡ„еҲӣж–°е’Ңз ”з©¶пјҢжөӘжҪ®дҝЎжҒҜжӯЈеңЁз§ҜжһҒжһ„е»әйқўеҗ‘з”ҹжҲҗејҸAIзҡ„з»ҝиүІејҖж”ҫеҠ йҖҹжҷәз®—е№іеҸ°гҖӮеҺ»е№ҙеҚҸеҗҢеҗҲдҪңдјҷдјҙеҸ‘еёғзҡ„ж¶ІеҶ·ејҖж”ҫеҠ йҖҹжҷәз®—дёӯеҝғи§ЈеҶіж–№жЎҲпјҢйҰ–е…Ҳе…·жңүйқһеёёй«ҳзҡ„з®—еҠӣжҖ§иғҪпјӣе…¶ж¬ЎпјҢеҸҜд»Ҙе®һзҺ°еҚғиҠҜзә§еӨ§и§„жЁЎжү©еұ•пјҢж”Ҝж’‘и¶…еҚғдәҝ规模模еһӢи®ӯз»ғпјӣеҗҢж—¶пјҢе…Ҳиҝӣж¶ІеҶ·жҠҖжңҜдҪҝж•ҙдёӘе№іеҸ°зҡ„PUEеӨ§е№…дјҳеҢ–гҖӮеҗҢж—¶пјҢжөӘжҪ®дҝЎжҒҜд№ҹеңЁз§ҜжһҒжһ„е»әе…Ёж ҲејҖж”ҫеҠ йҖҹжҷәз®—иғҪеҠӣпјҢйҷӨдәҶжҸҗдҫӣеә•еұӮзҡ„AIи®Ўз®—е№іеҸ°пјҢдёҠеұӮжңүAIиө„жәҗе№іеҸ°пјҢиғҪеӨҹеңЁиө„жәҗз®ЎзҗҶеұӮйҖҡиҝҮз»ҹдёҖжҺҘеҸЈе®һзҺ°еҜ№дәҺ30дҪҷз§ҚеӨҡе…ғз®—еҠӣиҠҜзүҮзҡ„з»ҹдёҖзҡ„и°ғеәҰе’Ңз®ЎзҗҶгҖӮеҶҚеҫҖдёҠжҳҜAIз®—жі•е№іеҸ°пјҢжҸҗдҫӣејҖжәҗзҡ„ж·ұеәҰеӯҰд№ з®—жі•жЎҶжһ¶гҖҒеӨ§жЁЎеһӢд»ҘеҸҠејҖж”ҫзҡ„ж•°жҚ®йӣҶгҖӮеңЁжӯӨд№ӢдёҠжҳҜз®—еҠӣжңҚеҠЎпјҢеҢ…жӢ¬з®—еҠӣгҖҒжЁЎеһӢж•°жҚ®гҖҒдәӨд»ҳгҖҒиҝҗз»ҙзӯүеӨҡз§ҚжңҚеҠЎжЁЎејҸгҖӮжңҖдёҠеұӮжҳҜжӢҘжңү4000еӨҡ家еҗҲдҪңдјҷдјҙзҡ„е…ғи„‘з”ҹжҖҒпјҢжөӘжҪ®дҝЎжҒҜе’Ңз”ҹжҖҒеҗҲдҪңдјҷдјҙе…ұеҗҢејҖеұ•ејҖж”ҫеҠ йҖҹи®Ўз®—ж–№жЎҲзҡ„и®ҫи®ЎпјҢ并жҲҗеҠҹең°жҺЁеҗ‘дә§дёҡиҗҪең°гҖӮеҹәдәҺејҖж”ҫеҠ йҖҹ规иҢғзҡ„AIи®Ўз®—е№іеҸ°зӣ®еүҚе·Із»ҸйҖӮй…Қ20еӨҡз§Қдёҡз•Ңдё»жөҒзҡ„еӨ§жЁЎеһӢпјҢеҢ…жӢ¬еӨ§е®¶йқһеёёзҶҹжӮүзҡ„GPTзі»еҲ—гҖҒLLaMAгҖҒChat GLMгҖҒвҖңжәҗвҖқпјҢеҗҢж—¶иҝҳж”ҜжҢҒеӨҡзұ»жү©ж•ЈжЁЎеһӢйҖӮй…ҚгҖӮ
вҖңеҠ©зҷҫиҠҜпјҢжҷәеҚғжЁЎвҖқ еҠ йҖҹеӨҡе…ғз®—еҠӣиҗҪең°
еңЁAIGCжҠҖжңҜе’Ңдә§дёҡеҝ«йҖҹеҸ‘еұ•иҝҮзЁӢдёӯпјҢиҷҪ然дёҡз•Ңе·Із»ҸеҲ¶е®ҡдәҶејҖж”ҫеҠ йҖҹи®Ўз®—зӣёе…іи§„иҢғпјҢдҪҶдә§дёҡиҗҪең°иҝҳеӯҳеңЁдёҖдәӣй—®йўҳгҖӮжҜ”еҰӮпјҢејҖж”ҫи®Ўз®—зі»з»ҹе®ҡеҲ¶еҢ–зЁӢеәҰй«ҳпјҢ规иҢғиҰҶзӣ–зҡ„йўҶеҹҹдёҚи¶іпјҢеҢ…жӢ¬еӨҡе…ғз®—еҠӣиҠҜзүҮзҡ„зі»з»ҹйҖӮй…ҚгҖҒз®ЎзҗҶе’Ңи°ғеәҰпјҢд»ҘеҸҠж·ұеәҰеӯҰд№ зҺҜеўғзҡ„йғЁзҪІзӯүзӯүгҖӮ
еңЁOAM规иҢғеҹәзЎҖдёҠпјҢж—ҘеүҚгҖҠејҖж”ҫеҠ йҖҹ规иҢғAIжңҚеҠЎеҷЁи®ҫи®ЎжҢҮеҚ—гҖӢеҸ‘еёғпјҢеҹәдәҺеҪ“еүҚAIGCдә§дёҡиғҢжҷҜдёӢе®ўжҲ·зҡ„з—ӣзӮ№пјҢе®ҡд№үдәҶејҖж”ҫеҠ йҖҹжңҚеҠЎеҷЁи®ҫи®Ўзҡ„еҺҹеҲҷпјҢеҢ…жӢ¬еә”з”ЁеҜјеҗ‘гҖҒеӨҡе…ғејҖж”ҫгҖҒз»ҝиүІй«ҳж•ҲгҖҒз»ҹзӯ№и®ҫи®ЎгҖӮеҗҢж—¶еҜ№жңҚеҠЎеҷЁи®ҫи®Ўж–№жі•иҝӣиЎҢж·ұеҢ–е’Ңз»ҶеҢ–пјҢеҢ…жӢ¬д»ҺиҠӮзӮ№еұӮеҲ°е№іеҸ°еұӮзҡ„еӨҡз»ҙеҚҸеҗҢи®ҫи®Ўж–№жЎҲгҖӮж–№жЎҲе……еҲҶиҖғйҮҸйҖӮй…Қе’Ңз ”еҸ‘иҝҮзЁӢдёӯйҒҮеҲ°зҡ„й—®йўҳпјҢиҝӣдёҖжӯҘз»ҶеҢ–дәҶиҠӮзӮ№еҲ°е№іеҸ°зҡ„и®ҫи®ЎеҸӮж•°пјҢжңҖз»Ҳзӣ®зҡ„жҳҜжҸҗй«ҳеӨҡе…ғз®—еҠӣиҠҜзүҮзҡ„ејҖеҸ‘е’ҢйҖӮй…ҚгҖҒйғЁзҪІж•ҲзҺҮгҖӮз”ұдәҺйқўеҗ‘AIGCи®ӯз»ғзҡ„жңҚеҠЎеҷЁе…·жңүйқһеёёеӨҡзҡ„й«ҳеҠҹиҖ—иҠҜзүҮд»ҘеҸҠй«ҳдә’иҒ”еёҰе®Ҫи®ҫи®ЎпјҢзЁіе®ҡжҖ§й—®йўҳдёҘеі»пјҢйңҖиҰҒжӣҙеҠ е…Ёйқўзҡ„жөӢиҜ•дҝқиҜҒзі»з»ҹзЁіе®ҡжҖ§пјҢеҮҸе°‘ж–ӯзӮ№зҡ„еҸ‘з”ҹе’ҢеҜ№еӨ§жЁЎеһӢи®ӯз»ғж•ҲзҺҮзҡ„еҪұе“ҚгҖӮеӣ жӯӨпјҢгҖҠжҢҮеҚ—гҖӢжҸҗдҫӣдәҶд»Һз»“жһ„гҖҒж•ЈзғӯгҖҒеҺӢеҠӣгҖҒзЁіе®ҡжҖ§гҖҒиҪҜ件兼容жҖ§зӯүе…Ёйқўзі»з»ҹзҡ„жөӢиҜ•жҢҮеҜјгҖӮ
жңҖеҗҺпјҢеӨҡе…ғз®—еҠӣиҰҒжҺЁеҗ‘дә§дёҡеә”з”ЁпјҢжңҖе…ій”®зҡ„жҳҜжҖ§иғҪпјҢеҢ…жӢ¬иҠҜзүҮжҖ§иғҪгҖҒдә’иҒ”жҖ§иғҪгҖҒжЁЎеһӢжҖ§иғҪд»ҘеҸҠиҷҡжӢҹеҢ–жҖ§иғҪгҖӮгҖҠжҢҮеҚ—гҖӢеҹәдәҺеүҚжңҹз§ҜзҙҜзҡ„Benchmarkи°ғдјҳз»ҸйӘҢпјҢжҸҗеҮәдәҶжҖ§иғҪжөӢиҜ„е’Ңи°ғдјҳж ҮеҮҶеҸҠж–№жі•пјҢеё®еҠ©еҗҲдҪңдјҷдјҙжӣҙеҝ«гҖҒжӣҙеҘҪең°е°Ҷ他们жңҖж–°зҡ„иҠҜзүҮдә§е“ҒжҺЁеҗ‘еә”з”ЁиҗҪең°пјҢжҸҗй«ҳз®—еҠӣзҡ„еҸҜз”ЁжҖ§гҖӮжңҖз»Ҳзӣ®ж ҮжҳҜжҺЁеҠЁж•ҙдёӘAIз®—еҠӣдә§дёҡзҡ„еҲӣж–°е’ҢеҸ‘еұ•пјҢеҚҸеҗҢдә§дёҡй“ҫдёҠдёӢжёёеҗҲдҪңдјҷдјҙжҺЁеҠЁж•ҙдёӘејҖж”ҫеҠ йҖҹз”ҹжҖҒпјҢе…ұеҗҢеә”еҜ№AIGCж—¶д»Јзҡ„з®—еҠӣжҢ‘жҲҳгҖӮ
и°ўи°ўеӨ§е®¶пјҒ
жөӘжҪ®дҝЎжҒҜеҲҶеёғејҸеӯҳеӮЁAS13000-HпјҢжөӘжҪ®дҝЎжҒҜAS13000-MеӯҳеӮЁе№іеҸ°пјҢжөӘжҪ®дҝЎжҒҜеӯҳеӮЁSSD NS6610G1
жҷәз®—OS

жҲҗйғҪ科жұҮ科жҠҖжңүйҷҗе…¬еҸё
ең°еқҖпјҡжҲҗйғҪеёӮдәәж°‘еҚ—и·Ҝеӣӣж®ө1еҸ·ж—¶д»Јж•°з ҒеӨ§еҺҰ18FA5
з”өиҜқпјҡ400-028-1235
жүӢжңәпјҡ180 8195 0517 пјҲеҫ®дҝЎеҗҢеҸ·пјү

